Why Data Scientists Love Kubernetes
 Sophie WatsonLet's start with an uncontroversial point: Software developers and system operators love Kubernetes as a way to deploy and manage applications in Linux containers. Linux containers provide the foundation for reproducible builds and deployments, but Kubernetes and its ecosystem provide essential features that make containers great for running real applications, like:
Sophie WatsonLet's start with an uncontroversial point: Software developers and system operators love Kubernetes as a way to deploy and manage applications in Linux containers. Linux containers provide the foundation for reproducible builds and deployments, but Kubernetes and its ecosystem provide essential features that make containers great for running real applications, like:
- Continuous integration and deployment, so you can go from a Git commit to a passing test suite to new code running in production
- Ubiquitous monitoring, which makes it easy to track the performance and other metrics about any component of a system and visualize them in meaningful ways
- Declarative deployments, which allow you to rely on Kubernetes to recreate your production environment in a staging environment
- Flexible service routing, which means you can scale services out or gradually roll updates out to production (and roll them back if necessary)
What you may not know is that Kubernetes also provides an unbeatable combination of features for working data scientists. The same features that streamline the software development workflow also support a data science workflow! To see why, let's first see what a data scientist's job looks like.
A data science project: predicting customer churn
Some people define data science broadly, including machine learning (ML), software engineering, distributed computing, data management, and statistics. Others define the field more narrowly as finding solutions to real-world problems by combining some domain expertise with machine learning or advanced statistics. We're not going to commit to an explicit definition of data scientist in this article, but we will tell you what data scientists might aim to do in a typical project and how they might do their work.

Consider a problem faced by any business with subscribing customers: Some might not renew. Customer churn detection seeks to proactively identify customers who are likely to not renew their contracts. Once these customers are identified, the business can choose to target their accounts with particular interventions (for example, sales calls or discounts) to make them less likely to leave. The overall churn-prevention problem has several parts: predicting which customers are likely to leave, identifying interventions that are likely to retain customers, and prioritizing which customers to target given a limited budget for interventions. A data scientist could work on any or all of these, but we'll use the first one as our running example.
The first part of the problem to solve is identifying an appropriate definition for "churn" to incorporate into a predictive model. We may have an intuitive definition of what it means to lose a customer, but a data scientist needs to formalize this definition, say, by defining the churn prediction problem as: "Given this customer's activity in the last 18 months, how likely are they to cancel their contract in the next six?"

The data scientist then needs to decide which data about a customer's activity the model should consider-in effect, fleshing out and formalizing the first part of the churn definition. Concretely, a data scientist might consider any information available about a customer's actual use of the company's products over the historical window, the size of their account, the number of customer-service interactions they've had, or even the tone of their comments on support tickets they've filed. The measurements or data that our model considers are called features.
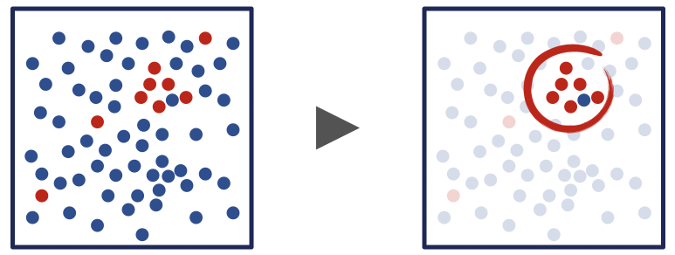
With a definition of churn and a set of features to consider, the data scientist can then begin exploratory analysis on historical data (that includes both the feature set and the ultimate outcome for a given customer in a given period). Exploratory analysis can include visualizing combinations of features and seeing how they correlate with whether a customer will churn. More generally, this part of the process seeks to identify structure in the historical data and whether it is possible to find a clean separation between retained customers and churning customers based on the data characterizing them.
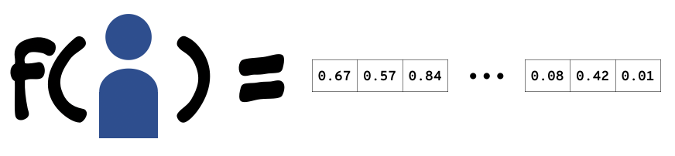
For some problems, it won't be obvious that there's structure in the data-in these cases, the data scientist will have to go back to the drawing board and identify some new data to collect or perhaps a novel way to encode or transform the data available. However, an exploratory analysis will often help a data scientist identify the features to consider while training a predictive model, as well as suggest some ways to transform those data. The data scientist's next job is feature engineering: finding a way to transform and encode the feature data-which might be in database tables, on event streams, or in data structures in a general-purpose programming language so that it's suitable for input to the algorithm that trains a model. This generally means encoding these features as vectors of floating-point numbers. Just any encoding won't do; the data scientist needs to find an encoding that preserves the structure of the features so similar customers map to similar vectors-or else the algorithm will perform poorly.
Only now is the data scientist ready to train a predictive model. For the problem of predicting whether a customer will churn, the model-training pipeline starts with labeled historical data about customers. It then uses the techniques developed in the feature-engineering process to extract features from raw data, resulting in vectors of floating-point numbers labeled with "true" or "false" and corresponding to customers that will or will not churn in the window of interest. The model-training algorithm takes this collection of feature vectors as input and optimizes a process to separate between true and false vectors in a way that minimizes error. The predictive model will ultimately be a function that takes a feature vector and returns true or false, indicating whether the customer corresponding to that vector is likely to churn or not.
At any point in this process, the data scientist may need to revisit prior phases-perhaps to refine a feature-engineering approach, to collect different data, or even to change the metric they are trying to predict. In this way, the data science workflow is a lot like the traditional software development lifecycle: problems discovered during implementation can force an engineer to change the design of an interface or choice of a data structure. These problems can even cascade all the way back to requirements analysis, forcing a broader rethinking of the project's fundamentals. Fortunately, Kubernetes can support the data scientist's workflow in the same way it can support the software development lifecycle.
 William BentonKubernetes for data science
William BentonKubernetes for data science
Data scientists have many of the same concerns that software engineers do: repeatable experiments (like repeatable builds); portable and reproducible environments (like having identical setups in development, stage, and production); credential management; tracking and monitoring metrics in production; flexible routing; and effortless scale-out. It's not hard to see some of the analogies between things application developers do with Kubernetes and things data scientists might want to do:
- Repeatable batch jobs, like CI/CD pipelines, are analogous to machine learning pipelines in that multiple coordinated stages need to work together in a reproducible way to process data; extract features; and train, test, and deploy models.
- Declarative configurations that describe the connections between services facilitate creating reproducible learning pipelines and models across platforms.
- Microservice architectures enable simple debugging of machine learning models within the pipeline and aid collaboration between data scientists and other members of their team.
Data scientists share many of the same challenges as application developers, but they have some unique challenges related to how data scientists work and to the fact that machine learning models can be more difficult to test and monitor than conventional services. We'll focus on one problem related to workflow.
Most data scientists do their exploratory work in interactive notebooks. Notebook environments, such as those developed by Project Jupyter, provide an interactive literate programming environment in which users can mix explanatory text and code; run and change the code; and inspect its output.
These properties make notebook environments wonderfully flexible for exploratory analysis. However, they are not an ideal software artifact for collaboration or publishing-imagine if the main way software developers published their work was by posting transcripts from interactive REPLs to a pastebin service.
Sharing an interactive notebook with a colleague is akin to sharing a physical one-there's some good information in there, but they have to do some digging to find it. And due to the fragility and dependency of a notebook on its environment, a colleague may see different output when they run your notebook-or worse: it may crash.
Kubernetes for data scientists
Data scientists may not want to become Kubernetes experts-and that's fine! One of the strengths of Kubernetes is that it is a powerful framework for building higher-level tools.
One such tool is the Binder service, which takes a Git repository of Jupyter notebooks, builds a container image to serve them, then launches the image in a Kubernetes cluster with an exposed route so you can access it from the public internet. Since one of the big downsides of notebooks is that their correctness and functionality can be dependent on their environment, having a high-level tool that can build an immutable environment to serve a notebook on Kubernetes eliminates a huge source of headaches.
It's possible to use the hosted Binder service or run your own Binder instance, but if you want a little more flexibility in the process, you can also use the source-to-image (S2I) workflow and tool along with Graham Dumpleton's Jupyter S2I images to roll your own notebook service. In fact, the source-to-image workflow is a great starting point for infrastructure or packaging experts to build high-level tools that subject matter experts can use. For example, the Seldon project uses S2I to simplify publishing model services-simply provide a model object to the builder, and it will build a container exposing it as a service.
A great thing about the source-to-image workflow is that it enables arbitrary actions and transformations on a source repository before building an image. As an example of how powerful this workflow can be, we've created an S2I builder image that takes as its input a Jupyter notebook that shows how to train a model. It then processes this notebook to identify its dependencies and extract a Python script to train and serialize the model. Given these, the builder installs the necessary dependencies and runs the script in order to train the model. The ultimate output of the builder is a REST web service that serves the model built by the notebook. You can see a video of this notebook-to-model-service S2I in action. Again, this isn't the sort of tool that a data scientist would necessarily develop, but creating tools like this is a great opportunity for Kubernetes and packaging experts to collaborate with data scientists.
Kubernetes for machine learning in production
Kubernetes has a lot to offer data scientists who are developing techniques to solve business problems with machine learning, but it also has a lot to offer the teams who put those techniques in production. Sometimes machine learning represents a separate production workload-a batch or streaming job to train models and provide insights-but machine learning is increasingly put into production as an essential component of an intelligent application.
The Kubeflow project is targeted at machine learning engineers who need to stand up and maintain machine learning workloads and pipelines on Kubernetes. Kubeflow is also an excellent distribution for infrastructure-savvy data scientists. It provides templates and custom resources to deploy a range of machine learning libraries and tools on Kubernetes.
Kubeflow is an excellent way to run frameworks like TensorFlow, JupyterHub, Seldon, and PyTorch under Kubernetes and thus represents a path to truly portable workloads: a data scientist or machine learning engineer can develop a pipeline on a laptop and deploy it anywhere. This is a very fast-moving community developing some cool technology, and you should check it out!
Radanalytics.io is a community project targeted at application developers, and it focuses on the unique demands of developing intelligent applications that depend on scale-out compute in containers. The radanalytics.io project includes a containerized Apache Spark distribution to support scalable data transformation and machine learning model training, as well as a Spark operator and Spark management interface. The community also supports the entire intelligent application lifecycle by providing templates and images for Jupyter notebooks, TensorFlow training and serving, and S2I builders that can deploy an application along with the scale-out compute resources it requires. If you want to get started building intelligent applications on OpenShift or Kubernetes, a great place to start is one of the many example applications or conference talks on radanalytics.io.
Sophie Watson & William Benton presented Why Data Scientists Love Kubernetes at KubeCon + CloudNativeCon North America, December 10-13 in Seattle.
About the authors
Sophie Watson - Sophie is a software engineer at Red Hat, where she works in an emerging technology group. She has a background in Mathematics and has recently completed a PhD in Bayesian statistics, in which she developed algorithms to estimate intractable quantities quickly and accurately. Since joining Red Hat in 2017, Sophie has focused on applying her data science and statistics skills to solving business problems and informing next-generation infrastructure for intelligent application development. She is...More about me
William Benton - William Benton leads a team of data scientists and engineers at Red Hat, where he has applied machine learning to problems ranging from forecasting cloud infrastructure costs to designing better cycling workouts. He has also conducted research and development in the areas of static program analysis, managed language runtimes, logic databases, cluster configuration management, and music technology. Will lives in the midwestern United States with his wife and three children and spends most of...More about me
| Why Data Scientists Love Kubernetes was authored by Sophie Watson and William Benton and published in Opensource.com. It is republished by Open Health News under the terms of the Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0). The original copy of the article can be found here. |
- Tags:
- Apache Spark
- Binder service
- data management
- data science workflow
- data scientists
- distributed computing
- Graham Dumpleton
- Jupyter notebooks
- JupyterHub
- Kubeflow project
- Kubernetes
- Linux Containers
- machine learning (ML)
- machine learning models
- microservice architectures
- open source
- OpenShift
- Project Jupyter
- PyTorch
- Radanalytics.io
- Seldon
- software engineering
- Sophie Watson
- source-to-image (S2I) workflow
- statistics
- TensorFlow
- William Benton
- Login to post comments